Efficient Serving of SpeechLMs with VoxServe
TL;DR: We present VoxServe, a high-throughput, low-latency serving system designed specifically for Speech Language Models (SpeechLMs). Unlike other LLM serving frameworks, VoxServe is built with speech as its primary focus, integrating functionalities such as audio detokenization and streaming generation into the core system. It offers a unified abstraction layer that supports a wide range of speech models through a single, consistent interface. In addition, VoxServe introduces a novel scheduling algorithm optimized for speech services with various scenarios.
Code is open-sourced here: https://github.com/vox-serve/vox-serve
In recent years, Speech Language Models (SpeechLMs), such as Text-to-Speech (TTS) and Speech-to-Speech (STS) models built on Language Model (LM) backbones, have gained significant traction. The release of powerful open-source models is opening up exciting opportunities for speech AI applications.
However, deploying these models in practice remains challenging:
- Lack of standardized abstractions. SpeechLMs vary widely in architecture, and there is no common framework to unify inference across them. This makes it difficult to switch between models.
- Limited focus on efficiency. To our knowledge, no inference system exists that is designed specifically for SpeechLMs with an emphasis on low-latency, high-throughput deployment. As a result, serving these models can be slow and costly.
In practice, each new speech model often comes with its own custom inference stack, which may not necessarily prioritize efficiency, making it cumbersome to switch between models. Repurposing existing LLM serving systems also demands significant effort due to fundamental differences in architecture and inference algorithms.
VoxServe addresses these challenges by providing a unified interface that supports diverse SpeechLMs, with high performance as the core design goal.
SpeechLM Background
Modern SpeechLMs typically consist of an LM backbone and an audio detokenizer model: the LM autoregressively generates discrete audio tokens, which the detokenizer then converts into continuous audio data.

Overview of typical SpeechLMs.
Serving these models efficiently poses unique challenges. At every inference step, two different models must run in tandem, while the resulting binary audio data needs to be streamed to the client. To enable stream generation, both models must be carefully scheduled at the right intervals.
Additionally, there are numerous model-specific complexities that complicate implementation, including multi-codebook modeling, depth transformers, audio input encoders, repetition penalties, and watermarking requirements. Audio detokenizers themselves vary widely in architecture, size, and latency characteristics, further increasing the difficulty.
For optimal serving performance, request scheduling must be carefully designed to account for both the LM backbone and the audio detokenizer.
VoxServe
We solve these challenges by designing VoxServe, a new serving system for SpeechLMs from the ground up. VoxServe currently supports the following four models, with more on the way:
The VoxServe model class is designed to natively support multi-stream inference, a common requirement for speech workloads. Its abstraction is carefully engineered to strike a balance between flexibility and efficiency, making it compatible with batch inference, CUDA graphs, and streaming.
A typical inference pipeline in VoxServe includes:
- Preprocessing: Preparing inputs for the LM backbone, such as prompt formatting, encoder inference, and metadata or masking setup for sampling.
- LM forward: Running the LM backbone to generate logits for the next tokens.
- Sampling: Selecting the next tokens from logits, which may involve algorithms like repetition penalty, classifier-free guidance, or filtering based on token type (e.g., audio vs. text tokens).
- (Optional) Depth forward: Executing the depth transformer for models that autoregressively generate tokens across multiple codebooks.
- Postprocessing: Converting tokens into audio data using the detokenizer, with a unified interface across diverse architectures.
By standardizing this workflow while remaining adaptable to model-specific variations, VoxServe simplifies deployment and ensures performance across a wide range of SpeechLMs.
Performance Optimizations
VoxServe goes beyond basic model inference, introducing optimizations specifically tailored to SpeechLMs in order to maximize performance.
Scheduling Algorithm
Since SpeechLMs comprise multiple components (the LM backbone and the audio detokenizer), the scheduling of requests between them has a direct impact on performance. Importantly, we note that speech applications differ in their performance requirements, so VoxServe implements specialized scheduling strategies for two distinct scenarios: online serving and offline serving.
Online serving scenarios: For interactive applications like voice chatbots, where many requests arrive in random intervals, we define the following two metrics:
- Time-To-First-Audio (TTFA): The latency from user input to the first audio chunk. Unlike Time-To-First-Token (TTFT) in LLMs, this requires generating multiple tokens and running the detokenizer (and sometimes the encoder) before producing the first chunk.
- Streaming Viability: Once the first audio chunk is ready, subsequent audio must be generated faster than the playback speed to prevent audio disruption that the client experiences.
A notable difference from text generation is that speed improvements beyond playback rate have diminishing returns (except for the first chunk), i.e., as long as the generation satisfies the real-time requirements, there is no benefit in generating faster than that. This opens the door to a scheduling strategy that prioritizes requests only when they are critical (either because the first audio chunk has not yet been produced or because streaming viability is at risk).
VoxServe classifies requests as critical or non-critical based on their current progress. Critical requests are prioritized, while non-critical ones can be delayed slightly to improve overall hardware utilization without hurting latency or streaming quality.
Intuitively, you can delay the inference of some part of the model for better hardware utilization, as long as it affects neither TTFA nor streaming viability.
Examples of online scheduling optimizations.
Offline serving scenarios: On the other hand, for workloads such as audiobook or podcast generation, the priority shifts from latency to throughput.
For offline serving, the performance metric is end-to-end throughput, which we measure by the Real-Time Factor (RTF), i.e., the total length of generated audio divided by the time it takes to generate it.
The scheduling strategy is simpler: maximize throughput by keeping hardware fully utilized, typically by running large batches at each stage (LM backbone and detokenizer).
Asynchronous Execution
To minimize overhead from complex scheduling and metadata processing, VoxServe adopts an asynchronous execution pipeline. Both the LM backbone and the audio detokenizer run asynchronously with respect to their schedulers, leveraging a delayed stop-decision mechanism (as proposed in NanoFlow).
Pipeline of asynchronous execution.
Evaluation
We evaluate the performance of VoxServe on Orpheus-3B model on a single H100 GPU. As a baseline, we compare against the official implementation provided by the model developers, which uses vLLM for LM backbone inference. All evaluations use greedy sampling with no repetition penalty.
For online serving, we measure TTFA and streaming viability rate (the fraction of audio chunks meeting real-time playback requirements) under varying request arrival rates (modeled as a Poisson distribution, with each request generating 1024 tokens).
The baseline system shows long TTFA and poor streaming viability, even under light loads. In contrast, VoxServe maintains low TTFA and meets real-time playback requirements thanks to its optimized detokenizer implementation, batching strategies, and use of CUDA graphs. By adopting the optimized scheduling algorithm, TTFA is kept low with an even higher request rate.
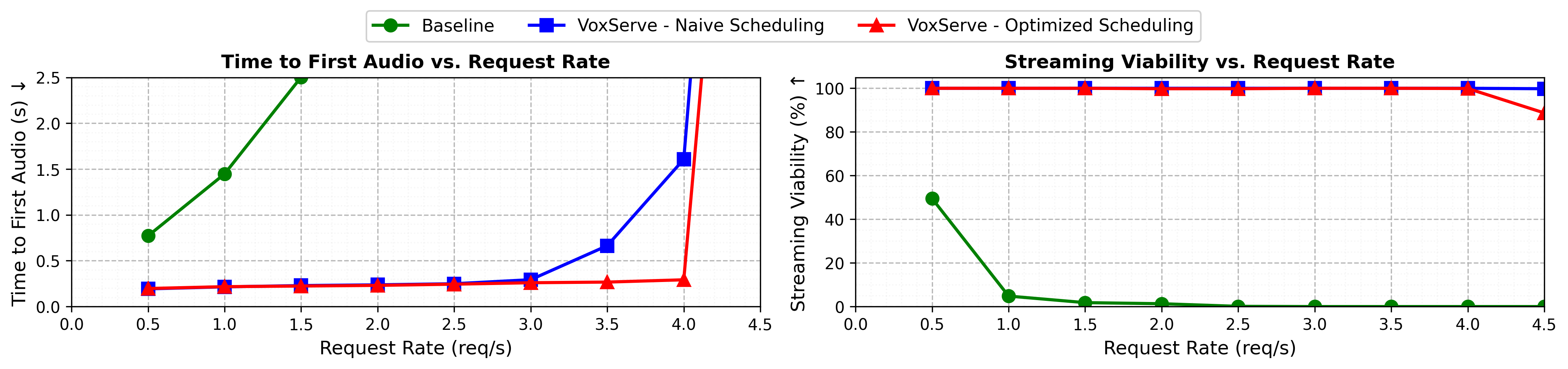
Performance for online serving scenario.
VoxServe achieves better throughput for the offline serving scenario as well. In an experiment processing 100 requests of equal length (1024 tokens), VoxServe significantly outperforms the baseline, owing to its coordinated scheduling of the LM backbone and audio detokenizer. With optimized scheduling enabled, throughput improves by an additional ~15%.
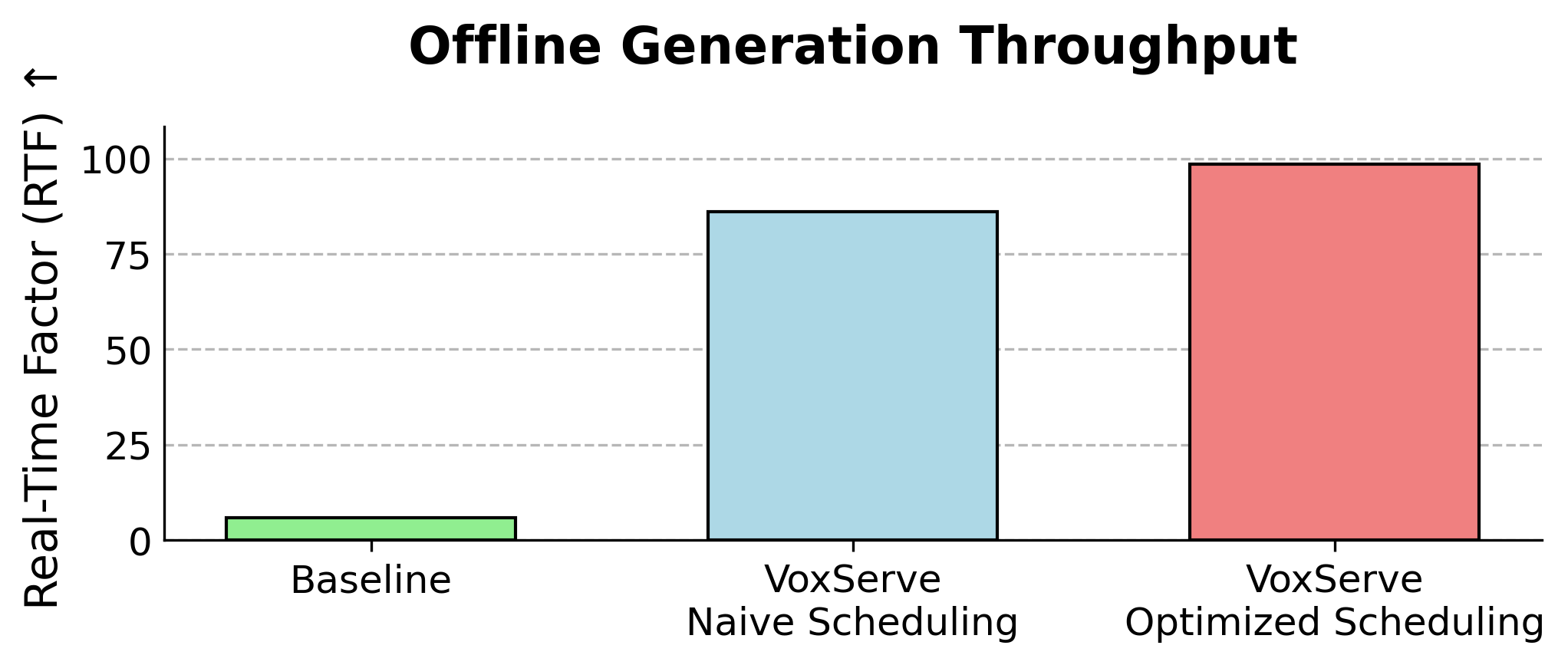
Performance for offline serving scenario.
What’s Next?
We are actively working on supporting more models and further performance improvements.
If you’d like to try it out, you can install VoxServe with:
pip install vox-serve
Also, please check out the code and feel free to post any requests or bug reports at our GitHub Issues.