Light-Speed Qwen3-TTS Serving at Scale with VoxServe
TL;DR: VoxServe now fully supports the Qwen3-TTS model family (Base, CustomVoice, and VoiceDesign) with true end-to-end streaming. You get streaming text input and audio output, chunked audio decoding, continuous batching, and CUDA Graph optimizations for high performance at scale.
Highlights
Ultra-low latency: VoxServe is built for real-time speech, delivering extremely low inference latency. In the demo below, a TTS request achieves a Time-To-First-Audio (TTFA) as low as 40 ms on an NVIDIA H100 GPU.
Real-time LLM chat integration: Qwen3-TTS supports incremental text input, and VoxServe supports that capability, making it easy to build end-to-end voice chatbots. The video below shows VoxServe connected to a local LLM, achieving low end-to-end response latency.
High throughput: VoxServe is optimized not just for low latency, but also for high-throughput serving under load. The figure below compares streaming performance against vLLM-Omni (v0.14.0) across increasing request rates. The y-axis reports TTFA (time to first audio chunk). The annotation boxes report streaming viability, i.e., the fraction of audio chunks delivered in time to avoid playback gaps on the client. All experiments follow the setup in our paper. The benchmark script is available here.
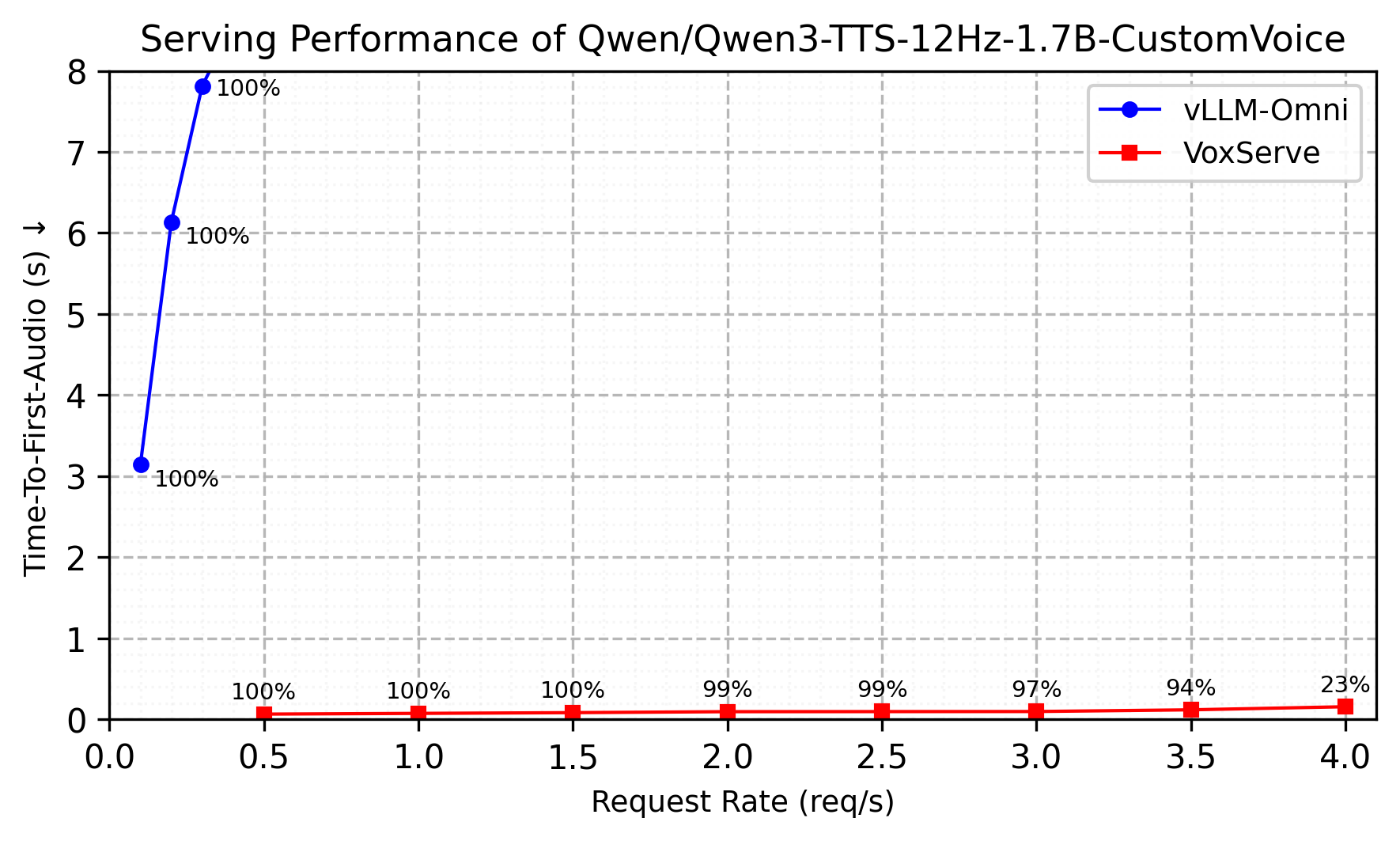
Serving performance.
While vLLM-Omni supports online serving for Qwen3-TTS, it does not currently support streaming audio generation, which keeps TTFA high even at low request rates. VoxServe treats streaming generation as a first-class objective, enabling effective batching while keeping TTFA low even under heavy concurrency.
Usage
Install VoxServe and serve a Qwen3-TTS checkpoint:
pip install vox-serve
vox-serve --model Qwen/Qwen3-TTS-12Hz-1.7B-Base --port 8000
Generate speech with a simple curl request:
curl -X POST "http://localhost:8000/generate" \
-F "text=Hello, this is a demonstration of Qwen3-TTS served by VoxServe." \
-F "streaming=true" \
-o output.wav
For detailed examples, see the Qwen3-TTS usage page:
We also provide an interactive playground for quick experimentation.
Technical Details
Qwen3-TTS is a state-of-the-art text-to-speech model from Alibaba’s Qwen team. It delivers strong audio quality, but serving it well is non-trivial: the architecture is multi-stage, supports multiple modes (Base, CustomVoice, VoiceDesign), and requires careful input/output streaming for low-latency inference.
VoxServe is a high-efficiency serving system built specifically for speech models. It provides a stable execution abstraction that accommodates a wide range of modern speech architectures, while enabling system-level optimizations like continuous batching, cache management, and CUDA Graph execution. As with many other models in our ecosystem, VoxServe supports the full Qwen3-TTS feature set with low latency in streaming scenarios.
Below, we outline how VoxServe maps cleanly onto Qwen3-TTS.
Model Architecture
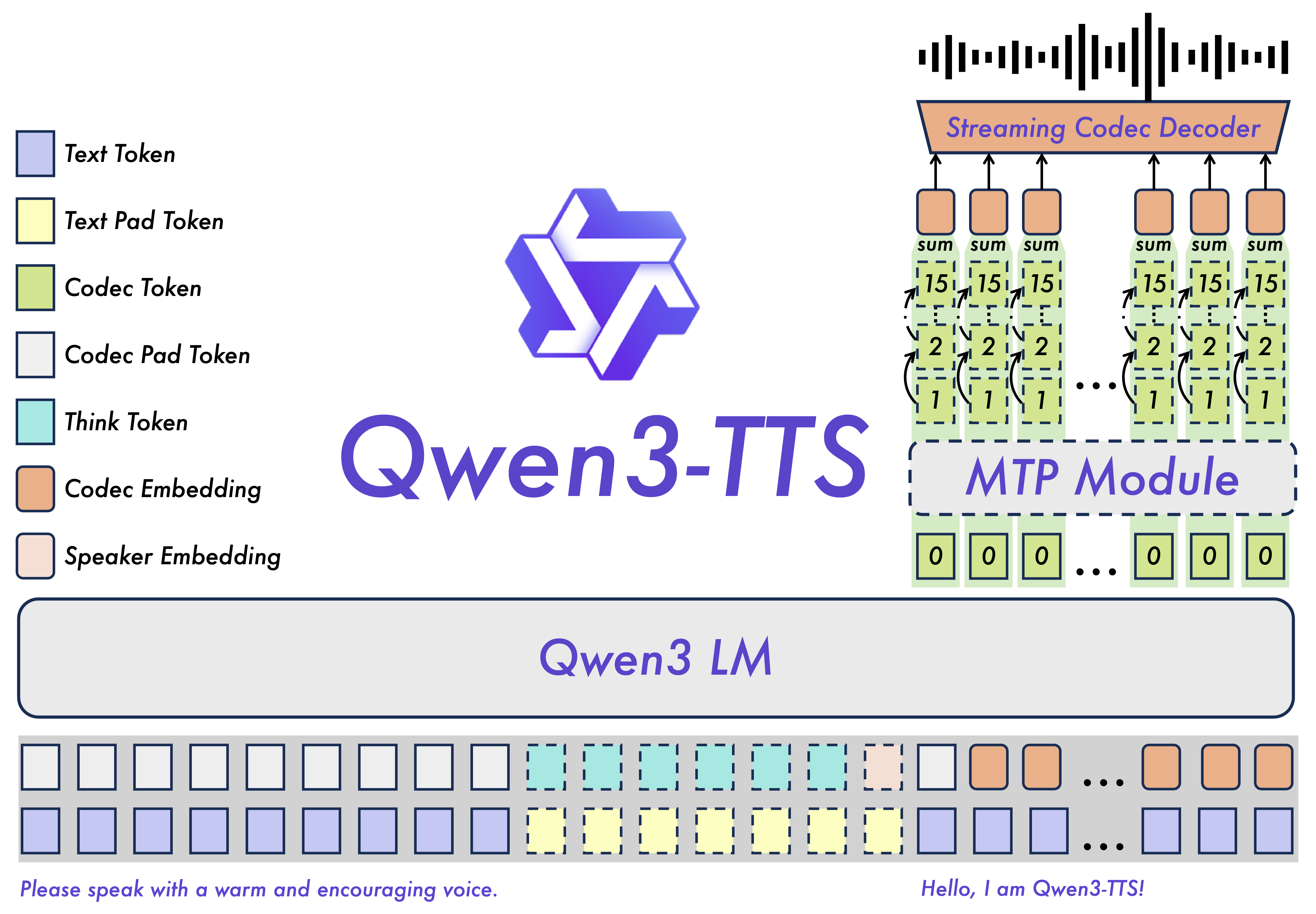
Model architecture of Qwen3-TTS.
Qwen3-TTS is composed of four major components:
- Speech Encoder: optionally encodes reference speech for voice cloning (Base variant)
- Qwen3 LM (Talker): generates speech tokens for codebook 0
- MTP Module (Codec Predictor): generates speech tokens for codebooks 1–15
- Streaming Codec Decoder: converts 16 codebooks into waveform audio
Three components (talker, codec predictor, and codec decoder) operate autoregressively. That creates engineering challenges around request scheduling, cache management, and GPU utilization. The codec decoder also includes audio-specific operations (e.g., convolutions) that introduce additional state to manage for streaming. Finally, the three Qwen3-TTS variants require different input configurations, adding more surface area to the serving stack.
Despite this complexity, the model fits naturally into VoxServe’s execution interface.
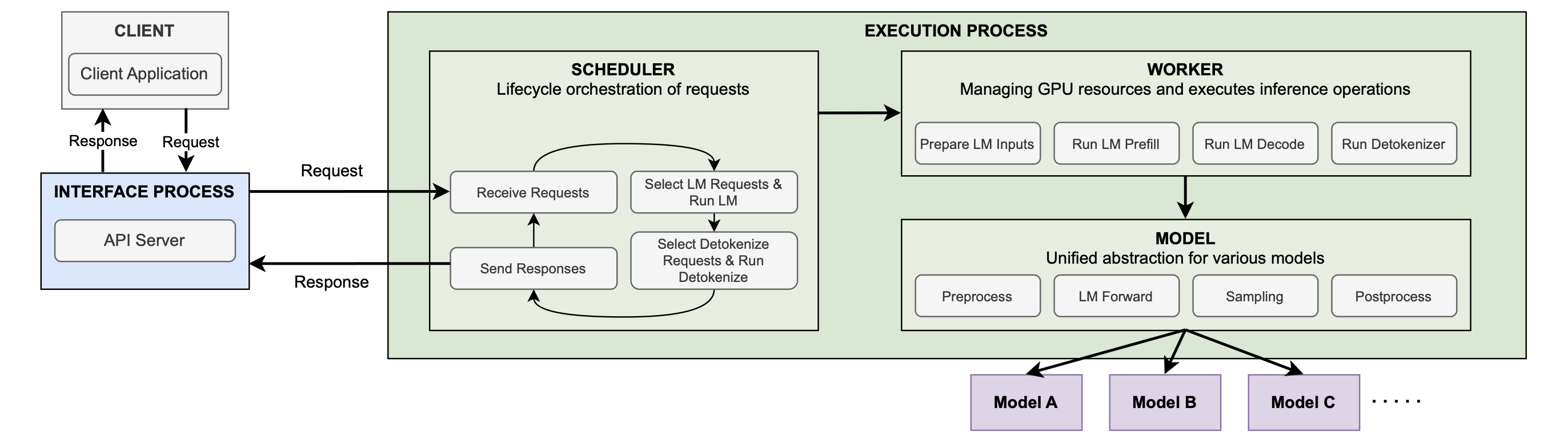
System design of VoxServe.
VoxServe implements a shared execution pipeline for all the models:
Preprocess → LM Forward → Sampling (→ Depth Forward → Depth Sampling) → Postprocess
- Preprocess: Formats inputs and runs the speech encoder when needed. Qwen3-TTS inputs vary by variant: speaker IDs for CustomVoice, reference audio/text for Base voice cloning, and instruction-style prompts for VoiceDesign.
- LM Forward & Sampling: Runs the talker (Qwen3 LM). Each step consumes a single text token plus 16 audio tokens, the content of which varies depending on whether input streaming is enabled, and voice cloning can additionally inject audio feature vectors. VoxServe’s interface supports this cleanly via three buffers:
input_ids,input_masks, andinput_features. We did not need to change this interface to support the full functionality of the Qwen3-TTS model. - Depth Forward & Sampling: Runs the codec predictor (MTP). VoxServe already supports this class of “depth” modules (e.g., in CSM-1B), so Qwen3-TTS plugs into an existing interface.
- Postprocess: Runs the codec decoder and emits waveform audio. For streaming, this stage requires cache management for both attention and convolutional layers. VoxServe already handled detokenizer caching for other models (e.g., CosyVoice 2); enabling it for Qwen3-TTS required just defining a new cache class and wiring the decoder to read/write cache state.
The key point is that we support Qwen3-TTS’s model-specific details without materially changing the layers above, such as the scheduler and worker in the diagram. That design choice matters because it lets existing system optimizations – continuous batching, KV/detokenizer cache management, CUDA Graph execution, and scheduling policies – apply to Qwen3-TTS with minimal friction. This is especially important for speech models, where architectures vary significantly across families. For deeper detail on the interface and optimizations, see our paper.
Input Streaming Implementation
VoxServe supports Qwen3-TTS’s incremental text input feature through a custom scheduler implementation.
VoxServe’s scheduler is explicitly designed to expose performance optimization hooks. In our paper, we describe streaming-oriented scheduling policies that prioritize low TTFA while preserving output streamability. This is implemented via request selection logic applied at each scheduler iteration.
Input streaming can be seamlessly supported in a similar way by swapping in a different scheduler implementation. The main challenge arises when audio generation outpaces incoming text; VoxServe addresses this by employing request selection rules that manage partially available input, ensuring the output stream remains smooth and uninterrupted.
Try VoxServe
VoxServe is fully open source on GitHub: https://github.com/vox-serve/vox-serve
Give it a try and let us know what you think!